|
||||
|
|
ЛЕКЦИЯ № 16. Программы на Ассемблере1. Структура программы на ассемблереПрограмма на ассемблере представляет собой совокупность блоков памяти, называемых сегментами памяти. Программа может состоять из одного или нескольких таких блоков-сегментов. Каждый сегмент содержит совокупность предложений языка, каждое из которых занимает отдельную строку кода программы. Предложения ассемблера бывают четырех типов: 1) команды или инструкции, представляющие собой символические аналоги машинных команд. В процессе трансляции инструкции ассемблера преобразуются в соответствующие команды системы команд микропроцессора; 2) макрокоманды. Это оформляемые определенным образом предложения текста программы, замещаемые во время трансляции другими предложениями; 3) директивы, являющиеся указанием транслятору ассемблера на выполнение некоторых действий. У директив нет аналогов в машинном представлении; 4) строки комментариев, содержащие любые символы, в том числе и буквы русского алфавита. Комментарии игнорируются транслятором. 2. Синтаксис ассемблераПредложения, составляющие программу, могут представлять собой синтаксическую конструкцию, соответствующую команде, макрокоманде, директиве или комментарию. Для того чтобы транслятор ассемблера мог распознать их, они должны формироваться по определенным синтаксическим правилам. Для этого лучше всего использовать формальное описание синтаксиса языка наподобие правил грамматики. Наиболее распространенные способы подобного описания языка программирования – синтаксические диаграммы и расширенные формы Бэкуса-Наура. Для практического использования более удобны синтаксические диаграммы. К примеру, синтаксис предложений ассемблера можно описать с помощью синтаксических диаграмм, показанных на следующих рисунках. 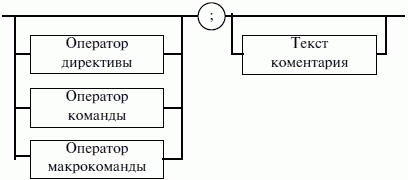 Рис. 4. Формат предложения ассемблера 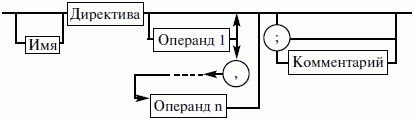 Рис. 5. Формат директив 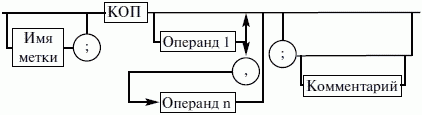 Рис. 6. Формат команд и макрокоманд На этих рисунках: 1) имя метки – идентификатор, значением которого является адрес первого байта того предложения исходного текста программы, которое он обозначает; 2) имя – идентификатор, отличающий данную директиву от других одноименных директив. В результате обработки ассемблером определенной директивы этому имени могут быть присвоены определенные характеристики; 3) код операции (КОП) и директива – это мнемонические обозначения соответствующей машинной команды, макрокоманды или директивы транслятора; 4) операнды – части команды, макрокоманды или директивы ассемблера, обозначающие объекты, над которыми производятся действия. Операнды ассемблера описываются выражениями с числовыми и текстовыми константами, метками и идентификаторами переменных с использованием знаков операций и некоторых зарезервированных слов. Как использовать синтаксические диаграммы? Очень просто: для этого нужно всего лишь найти и затем пройти путь от входа диаграммы (слева) к ее выходу (направо). Если такой путь существует, то предложение или конструкция синтаксически правильны. Если такого пути нет, значит, эту конструкцию компилятор не примет. При работе с синтаксическими диаграммами обращайте внимание на направление обхода, указываемое стрелками, так как среди путей могут быть и такие, по которым можно идти справа налево. По сути, синтаксические диаграммы отражают логику работы транслятора при разборе входных предложений программы. Допустимыми символами при написании текста программ являются: 1) все латинские буквы: А – Z, а – z. При этом заглавные и строчные буквы считаются эквивалентными; 2) цифры от 0 до 9; 3) знаки ?, @, S, _, &; 4) разделители. Предложения ассемблера формируются из лексем, представляющих собой синтаксически неразделимые последовательности допустимых символов языка, имеющие смысл для транслятора. Лексемами являются следующие. 1. Идентификаторы – последовательности допустимых символов, использующиеся для обозначения таких объектов программы, как коды операций, имена переменных и названия меток. Правило записи идентификаторов заключается в следующем: идентификатор может состоять из одного или нескольких символов. В качестве символов можно использовать буквы латинского алфавита, цифры и некоторые специальные знаки – _, ?, $, @. Идентификатор не может начинаться символом цифры. Длина идентификатора может быть до 255 символов, хотя транслятор воспринимает лишь первые 32, а остальные игнорирует. Регулировать длину возможных идентификаторов можно с использованием опции командной строки mv. Кроме этого, существует возможность указать транслятору на то, чтобы он различал прописные и строчные буквы либо игнорировал их различие (что и делается по умолчанию). Для этого применяются опции командной строки /mu, /ml, /mx. 2. Цепочки символов – последовательности символов, заключенные в одинарные или двойные кавычки. 3. Целые числа в одной из следующих систем счисления: двоичной, десятичной, шестнадцатеричной. Отождествление чисел при записи их в программах на ассемблере производится по определенным правилам: 1) десятичные числа не требуют для своего отождествления указания каких-либо дополнительных символов, например 25 или 139; 2) для отождествления в исходном тексте программы двоичных чисел необходимо после записи нулей и единиц, входящих в их состав, поставить латинское «b», например 10010101 b; 3) Шестнадцатеричные числа имеют больше условностей при своей записи: а) во-первых, они состоят из цифр 0…9, строчных и прописных букв латинского алфавита а, b, с, d, е, Гили Д В, С, D, Е, Е б) во-вторых, у транслятора могут возникнуть трудности с распознаванием шестнадцатеричных чисел из-за того, что они могут состоять как из одних цифр 0…9 (например, 190845), так и начинаться с буквы латинского алфавита (например, efl5). Для того, чтобы «объяснить» транслятору, что данная лексема не является десятичным числом или идентификатором, программист должен специальным образом выделять шестнадцатеричное число. Для этого на конце последовательности шестнадцатеричных цифр, составляющих шестнадцатеричное число, записывают латинскую букву «h». Это обязательное условие. Если шестнадцатеричное число начинается с буквы, то перед ним записывается ведущий нуль: 0 efl5 h. Таким образом, мы разобрались с тем, как конструируются предложения программы ассемблера. Но это лишь самый поверхностный взгляд. Практически каждое предложение содержит описание объекта, над которым или при помощи которого выполняется некоторое действие. Эти объекты называются операндами. Их можно определить так: операнды – это объекты (некоторые значения, регистры или ячейки памяти), на которые действуют инструкции или директивы, либо это объекты, которые определяют или уточняют действие инструкций или директив. Операнды могут комбинироваться с арифметическими, логическими, побитовыми и атрибутивными операторами для расчета некоторого значения или определения ячейки памяти, на которую будет воздействовать данная команда или директива. Рассмотрим подробнее характеристику операндов в нижеприведенной классификации: 1) постоянные или непосредственные операнды – число, строка, имя или выражение, имеющие некоторое фиксированное значение. Имя не должно быть перемещаемым, т. е. зависеть от адреса загрузки программы в память. К примеру, оно может быть определено операторами equ или =; 2) адресные операнды, задают физическое расположение операнда в памяти с помощью указания двух составляющих адреса: сегмента и смещения (рис. 7); 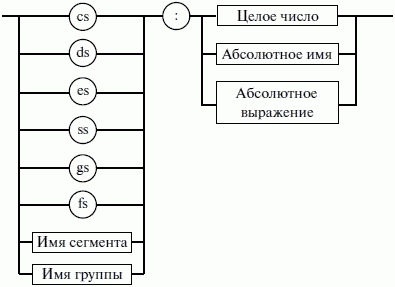 Рис. 7. Синтаксис описания адресных операндов 3) перемещаемые операнды – любые символьные имена, представляющие некоторые адреса памяти. Эти адреса могут обозначать местоположение в памяти некоторых инструкций (если операнд – метка) или данных (если операнд – имя области памяти в сегменте данных). Перемещаемые операнды отличаются от адресных тем, что они не привязаны к конкретному адресу физической памяти. Сегментная составляющая адреса перемещаемого операнда неизвестна и будет определена после загрузки программы в память для выполнения. Счетчик адреса – специфический вид операнда. Он обозначается знаком S. Специфика этого операнда в том, что когда транслятор ассемблера встречает в исходной программе этот символ, то он подставляет вместо него текущее значение счетчика адреса. Значение счетчика адреса или, как его иногда называют, счетчика размещения представляет собой смещение текущей машинной команды относительно начала сегмента кода. В формате листинга счетчику адреса соответствует вторая или третья колонка (в зависимости от того, присутствует или нет в листинге колонка с уровнем вложенности). Если взять в качестве примера любой листинг, то видно, что при обработке транслятором очередной команды ассемблера счетчик адреса увеличивается на длину сформированной машинной команды. Важно правильно понимать этот момент. К примеру, обработка директив ассемблера не влечет за собой изменения счетчика. Директивы, в отличие от команд ассемблера, – это лишь указания транслятору на выполнение определенных действий по формированию машинного представления программы, и для них транслятором не генерируется никаких конструкций в памяти. При использовании подобного выражения для перехода не забывайте о длине самой команды, в которой это выражение используется, так как значение счетчика адреса соответствует смещению в сегменте команд данной, а не следующей за ней команды. В нашем примере команда jmp занимает 2 байта. Но будьте осторожны, длина команды зависит от того, какие в ней используются операнды. Команда с регистровыми операндами будет короче команды, один из операндов которой расположен в память. В большинстве случаев эту информацию можно получить, зная формат машинной команды и анализируя колонку листинга с объектным кодом команды; 4) регистровый операнд – это просто имя регистра. В программе на ассемблере можно использовать имена всех регистров общего назначения и большинства системных регистров; 5) базовый и индексный операнды. Этот тип операндов используется для реализации косвенной базовой, косвенной индексной адресации или их комбинаций и расширений; 6) структурные операнды используются для доступа к конкретному элементу сложного типа данных, называемого структурой. Записи (аналогично структурному типу) используются для доступа к битовому полю некоторой записи. Операнды являются элементарными компонентами, из которых формируется часть машинной команды, обозначающая объекты, над которыми выполняется операция. В более общем случае операнды могут входить как составные части в более сложные образования, называемые выражениями. Выражения представляют собой комбинации операндов и операторов, рассматриваемые как единое целое. Результатом вычисления выражения может быть адрес некоторой ячейки памяти или некоторое константное (абсолютное) значение. Возможные типы операндов мы уже рассмотрели. Перечислим теперь возможные типы операторов ассемблера и синтаксические правила формирования выражений ассемблера, и дадим краткую характеристику операторов. 1. Арифметические операторы. К ним относятся: 1) унарные «+» и «—»; 2) бинарные «+» и «—»; 3) умножения «*»; 4) целочисленного деления «/»; 5) получения остатка от деления «mod». Эти операторы расположены на уровнях приоритета 6,7,8 в таблице 4. 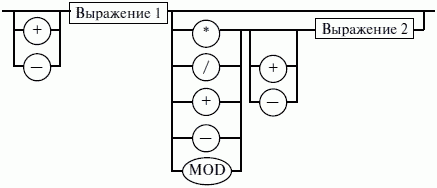 Рис. 8. Синтаксис арифметических операций 2. Операторы сдвига выполняют сдвиг выражения на указанное количество разрядов (рис. 9). 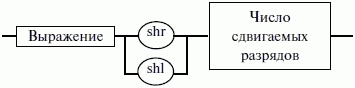 Рис. 9. Синтаксис операторов сдвига 3. Операторы сравнения (возвращают значение «истина» или «ложь») предназначены для формирования логических выражений (рис. 10 и табл. 3). Логическое значение «истина» соответствует цифровой единице, а «ложь» – нулю. 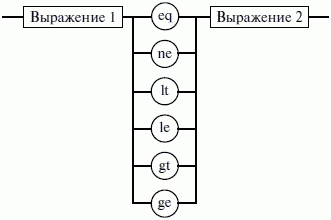 Рис. 10. Синтаксис операторов сравнения Таблица 3. Операторы сравнения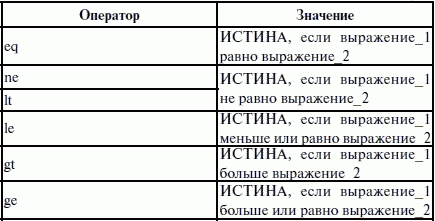 4. Логические операторы выполняют над выражениями побитовые операции (рис. 11). Выражения должны быть абсолютными, т. е. такими, численное значение которых может быть вычислено транслятором. 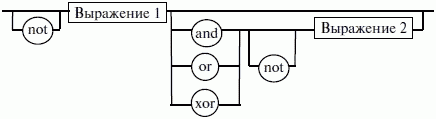 Рис. 11. Синтаксис логических операторов 5. Индексный оператор []. Скобки тоже являются оператором, и транслятор их наличие воспринимает как указание сложить значение выражение_1 за этими скобками с выражение_2, заключенным в скобки (рис. 12).  Рис. 12. Синтаксис индексного оператора Заметим, что в литературе по ассемблеру принято следующее обозначение: когда в тексте речь идет о содержимом регистра, то его название берут в круглые скобки. Мы также будем придерживаться этого обозначения. 6. Оператор переопределения типа ptr применяется для переопределения или уточнения типа метки или переменной, определяемых выражением (рис. 13). Тип может принимать одно из следующих значений: byte, word, dword, qword, tbyte, near, far. 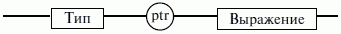 Рис. 13. Синтаксис оператора переопределения типа 7. Оператор переопределения сегмента «:» (двоеточие) заставляет вычислять физический адрес относительно конкретно задаваемой сегментной составляющей: «имя сегментного регистра», «имя сегмента» из соответствующей директивы SEGMENT или «имя группы» (рис. 14). При обсуждении сегментации мы говорили о том, что микропроцессор на аппаратном уровне поддерживает три типа сегментов – кода, стека и данных. В чем заключается такая аппаратная поддержка? К примеру, для выборки на выполнение очередной команды микропроцессор должен обязательно посмотреть содержимое сегментного регистра cs и только его. А в этом регистре, как мы знаем, содержится (пока еще не сдвинутый) физический адрес начала сегмента команд. Для получения адреса конкретной команды микропроцессору остается умножить содержимое cs на 16 (что означает сдвиг на четыре разряда) и сложить полученное 20-битное значение с 16-битным содержимым регистра ip. Примерно то же самое происходит и тогда, когда микропроцессор обрабатывает операнды в машинной команде. Если он видит, что операнд – это адрес (эффективный адрес, который является только частью физического адреса), то он знает, в каком сегменте его искать, – по умолчанию это сегмент, адрес начала которого записан в сегментном регистре ds. А что же с сегментом стека? В контексте нашего рассмотрения нас интересуют регистры sp и Ър. Если микропроцессор видит в качестве операнда (или его части, если операнд – выражение) один из этих регистров, то по умолчанию он формирует физический адрес операнда, используя в качестве его сегментной составляющей содержимое регистра ss. Это набор микропрограмм в блоке микропрограммного управления, каждая из которых выполняет одну из команд в системе машинных команд микропроцессора. Каждая микропрограмма работает по своему алгоритму. Изменить его, конечно, нельзя, но можно чуть-чуть подкорректировать. Делается это с помощью необязательного поля префикса машинной команды. Если мы согласны с тем, как работает команда, то это поле отсутствует. Если же мы хотим внести поправку (если, конечно, она допустима для конкретной команды) в алгоритм работы команды, то необходимо сформировать соответствующий префикс. Префикс представляет собой однобайтовую величину, численное значение которой определяет ее назначение. Микропроцессор распознает по указанному значению, что этот байт является префиксом, и дальнейшая работа микропрограммы выполняется с учетом поступившего указания на корректировку ее работы. Сейчас нас интересует один из них – префикс замены (переопределения) сегмента. Его назначение состоит в том, чтобы указать микропроцессору (а по сути, микропрограмме) на то, что мы не хотим использовать сегмент по умолчанию. Возможности для подобного переопределения, конечно, ограничены. Сегмент команд переопределить нельзя, адрес очередной исполняемой команды однозначно определяется парой cs: ip. А вот сегменты стека и данных – можно. Для этого и предназначен оператор «:». Транслятор ассемблера, обрабатывая этот оператор, формирует соответствующий однобайтовый префикс замены сегмента. 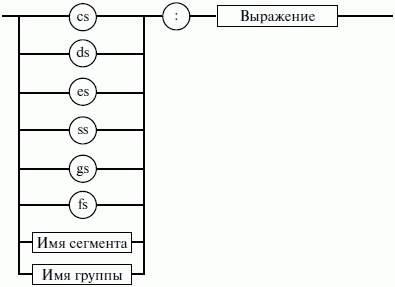 Рис. 14. Синтаксис оператора переопределения сегмента 8. Оператор именования типа структуры «.»(точка) также заставляет транслятор производить определенные вычисления, если он встречается в выражении. 9. Оператор получения сегментной составляющей адреса выражения seg возвращает физический адрес сегмента для выражения (рис. 15), в качестве которого могут выступать метка, переменная, имя сегмента, имя группы или некоторое символическое имя.  Рис. 15. Синтаксис оператора получения сегментной составляющей 10. Оператор получения смещения выражения offset позволяет получить значение смещения выражения (рис. 16) в байтах относительно начала того сегмента, в котором выражение определено.  Рис. 16. Синтаксис оператора получения смещения Как и в языках высокого уровня, выполнение операторов ассемблера при вычислении выражений осуществляется в соответствии с их приоритетами (табл. 4). Операции с одинаковыми приоритетами выполняются последовательно слева направо. Изменение порядка выполнения возможно путем расстановки круглых скобок, которые имеют наивысший приоритет. Таблица 4. Операторы и их приоритет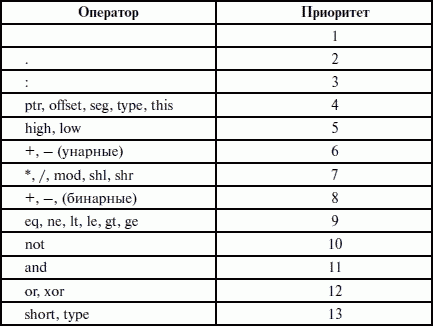 3. Директивы сегментацииВ ходе предыдущего обсуждения мы выяснили все основные правила записи команд и операндов в программе на ассемблере. Открытым остался вопрос о том, как правильно оформить последовательность команд, чтобы транслятор мог их обработать, а микропроцессор – выполнить. При рассмотрении архитектуры микропроцессора мы узнали, что он имеет шесть сегментных регистров, посредством которых может одновременно работать: 1) с одним сегментом кода; 2) с одним сегментом стека; 3) с одним сегментом данных; 4) с тремя дополнительными сегментами данных. Еще раз вспомним, что физически сегмент представляет собой область памяти, занятую командами и (или) данными, адреса которых вычисляются относительно значения в соответствующем сегментном регистре. Синтаксическое описание сегмента на ассемблере представляет собой конструкцию, изображенную на рисунке 17: 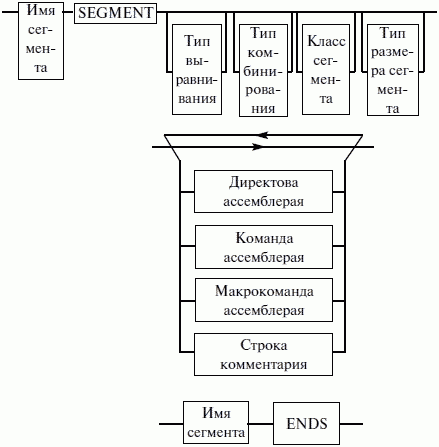 Рис. 17. Синтаксис описания сегмента Важно отметить, что функциональное назначение сегмента несколько шире, чем простое разбиение программы на блоки кода, данных и стека. Сегментация является частью более общего механизма, связанного с концепцией модульного программирования. Она предполагает унификацию оформления объектных модулей, создаваемых компилятором, в том числе с разных языков программирования. Это позволяет объединять программы, написанные на разных языках. Именно для реализации различных вариантов такого объединения и предназначены операнды в директиве SEGMENT. Рассмотрим их подробнее. 1. Атрибут выравнивания сегмента (тип выравнивания) сообщает компоновщику о том, что нужно обеспечить размещение начала сегмента на заданной границе. Это важно, поскольку при правильном выравнивании доступ к данным в процессорах i80x86 выполняется быстрее. Допустимые значения этого атрибута следующие: 1) BYTE – выравнивание не выполняется. Сегмент может начинаться с любого адреса памяти; 2) WORD – сегмент начинается по адресу, кратному двум, т. е. последний (младший) значащий бит физического адреса равен 0 (выравнивание на границу слова); 3) DWORD – сегмент начинается по адресу, кратному четырем, т. е. два последних (младших) значащих бита равны 0 (выравнивание на границу двойного слова); 4) PARA – сегмент начинается по адресу, кратному 16, т. е. последняя шестнадцатеричная цифра адреса должна быть Oh (выравнивание на границу параграфа); 5) PAGE – сегмент начинается по адресу, кратному 256, т. е. две последние шестнадцатеричные цифры должны быть 00h (выравнивание на границу 256-байтной страницы); 6) MEMPAGE – сегмент начинается по адресу, кратному 4 Кбайт, т. е. три последние шестнадцатеричные цифры должны быть OOOh (адрес следующей 4-Кбайтной страницы памяти). По умолчанию тип выравнивания имеет значение PARA. 2. Атрибут комбинирования сегментов (комбинаторный тип) сообщает компоновщику, как нужно комбинировать сегменты различных модулей, имеющие одно и то же имя. Значениями атрибута комбинирования сегмента могут быть: 1) PRIVATE – сегмент не будет объединяться с другими сегментами с тем же именем вне данного модуля; 2) PUBLIC – заставляет компоновщик соединить все сегменты с одинаковыми именами. Новый объединенный сегмент будет целым и непрерывным. Все адреса (смещения) объектов, а это могут быть в зависимости от типа сегмента команды и данные, будут вычисляться относительно начала этого нового сегмента; 3) COMMON – располагает все сегменты с одним и тем же именем по одному адресу. Все сегменты с данным именем будут перекрываться и совместно использовать память. Размер полученного в результате сегмента будет равен размеру самого большого сегмента; 4) AT хххх – располагает сегмент по абсолютному адресу параграфа (параграф – объем памяти, кратный 16; поэтому последняя шестнадцатеричная цифра адреса параграфа равна 0). Абсолютный адрес параграфа задается выражением ххх. Компоновщик располагает сегмент по заданному адресу памяти (это можно использовать, например, для доступа к видеопамяти или области ПЗ>), учитывая атрибут комбинирования. Физически это означает, что сегмент при загрузке в память будет расположен, начиная с этого абсолютного адреса параграфа, но для доступа к нему в соответствующий сегментный регистр должно быть загружено заданное в атрибуте значение. Все метки и адреса в определенном таким образом сегменте отсчитывают – ся относительно заданного абсолютного адреса; 5) STACK – определение сегмента стека. Заставляет компоновщик соединить все одноименные сегменты и вычислять адреса в этих сегментах относительно регистра ss. Комбинированный тип STACK (стек) аналогичен комбинированному типу PUBLIC, за исключением того, что регистр ss является стандартным сегментным регистром для сегментов стека. Регистр sp устанавливается на конец объединенного сегмента стека. Если не указано ни одного сегмента стека, компоновщик выдаст предупреждение, что стековый сегмент не найден. Если сегмент стека создан, а комбинированный тип STACK не используется, программист должен явно загрузить в регистр ss адрес сегмента (подобно тому, как это делается для регистра ds). По умолчанию атрибут комбинирования принимает значение PRIVATE. 3. Атрибут класса сегмента (тип класса) – это заключенная в кавычки строка, помогающая компоновщику определить соответствующий порядок следования сегментов при собирании программы из сегментов нескольких модулей. Компоновщик объединяет вместе в памяти все сегменты с одним и тем же именем класса (имя класса в общем случае может быть любым, но лучше, если оно будет отражать функциональное назначение сегмента). Типичным примером использования имени класса является объединение в группу всех сегментов кода программы (обычно для этого используется класс «code»). С помощью механизма типизации класса можно группировать также сегменты инициализированных и неинициализированных данных. 4. Атрибут размера сегмента. Для процессоров i80386 и выше сегменты могут быть 16– или 32-разрядными. Это влияет прежде всего на размер сегмента и порядок формирования физического адреса внутри него. Атрибут может принимать следующие значения: 1) USE16 – это означает, что сегмент допускает 16-разрядную адресацию. При формировании физического адреса может использоваться только 16-разрядное смещение. Соответственно, такой сегмент может содержать до 64 Кбайт кода или данных; 2)USE32 – сегмент будет 32-разрядным. При формировании физического адреса может использоваться 32-разрядное смещение. Поэтому такой сегмент может содержать до 4 Гбайт кода или данных. Все сегменты сами по себе равноправны, так как директивы SEGMENT и ENDS не содержат информации о функциональном назначении сегментов. Для того чтобы использовать их как сегменты кода, данных или стека, необходимо предварительно сообщить транслятору об этом, для чего используют специальную директиву ASSUME, имеющую формат, показанный на рис. 18. Эта директива сообщает транслятору о том, какой сегмент к какому сегментному регистру привязан. В свою очередь, это позволит транслятору корректно связывать символические имена, определенные в сегментах. Привязка сегментов к сегментным регистрам осуществляется с помощью операндов этой директивы, в которых имя_сегмента должно быть именем сегмента, определенным в исходном тексте программы директивой SEGMENT или ключевым словом nothing. Если в качестве операнда используется только ключевое слово nothing, то предшествующие назначения сегментных регистров аннулируются, причем сразу для всех шести сегментных регистров. Но ключевое слово nothing можно использовать вместо аргумента имя сегмента; в этом случае будет выборочно разрываться связь между сегментом с именем имя сегмента и соответствующим сегментным регистром (см. рис. 18). 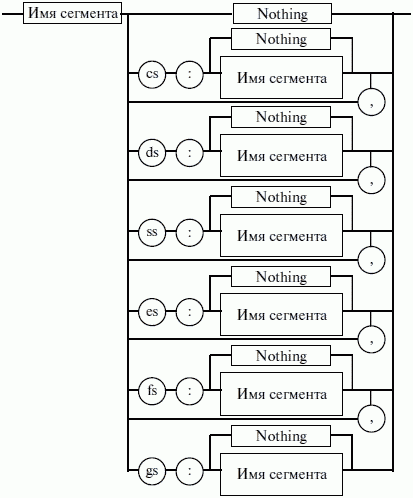 Рис. 18. Директива ASSUME Для простых программ, содержащих по одному сегменту для кода, данных и стека, хотелось бы упростить ее описание. Для этого в трансляторы MASM и TASM ввели возможность использования упрощенных директив сегментации. Но здесь возникла проблема, связанная с тем, что необходимо было как-то компенсировать невозможность напрямую управлять размещением и комбинированием сегментов. Для этого совместно с упрощенными директивами сегментации стали использовать директиву указания модели памяти MODEL, которая частично стала управлять размещением сегментов и выполнять функции директивы ASSUME (поэтому при использовании упрощенных директив сегментации директиву ASSUME можно не использовать). Эта директива связывает сегменты, которые в случае использования упрощенных директив сегментации имеют предопределенные имена, с сегментными регистрами (хотя явно инициализировать ds все равно придется). Синтаксис директивы MODEL показан на рисунке 19. 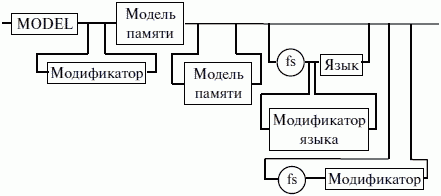 Рис. 19. Синтаксис директивы MODEL Обязательным параметром директивы MODEL является модель памяти. Этот параметр определяет модель сегментации памяти для программного модуля. Предполагается, что программный модуль может иметь только определенные типы сегментов, которые определяются упомянутыми нами ранее упрощенными директивами описания сегментов. Эти директивы приведены в таблице 5. Таблица 5. Упрощенные директивы определения сегмента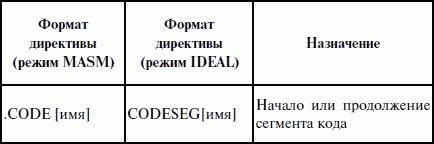 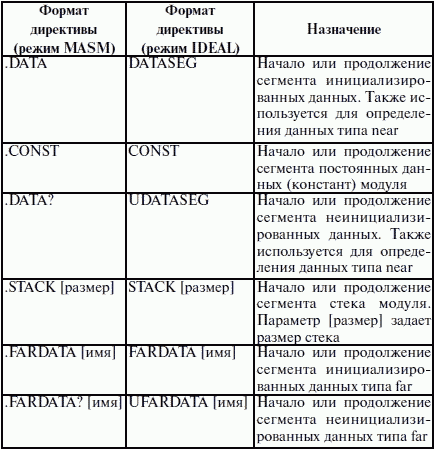 Наличие в некоторых директивах параметра [имя] говорит о том, что возможно определение нескольких сегментов этого типа. С другой стороны, наличие нескольких видов сегментов данных обусловлено требованием обеспечить совместимость с некоторыми компиляторами языков высокого уровня, которые создают разные сегменты данных для инициализированных и неинициализированных данных, а также констант. При использовании директивы MODEL транслятор делает доступными несколько идентификаторов, к которым можно обращаться во время работы программы, с тем, чтобы получить информацию о тех или иных характеристиках данной модели памяти (табл. 7). Перечислим эти идентификаторы и их значения (табл. 6). Таблица 6. Идентификаторы, создаваемые директивой MODEL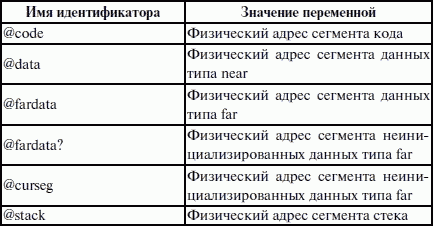 Теперь можно закончить обсуждение директивы MODEL. Операнды директивы MODEL используют для задания модели памяти, которая определяет набор сегментов программы, размеры сегментов данных и кода, способ связывания сегментов и сегментных регистров. В таблице 7 приведены некоторые значения параметра «модель памяти» директивы MODEL. Таблица 7. Модели памяти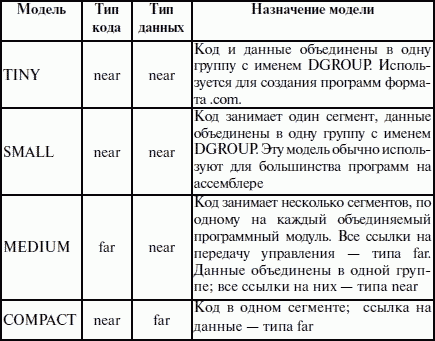  Параметр «модификатор» директивы MODEL позволяет уточнить некоторые особенности использования выбранной модели памяти (табл. 8). Таблица 8. Модификаторы модели памяти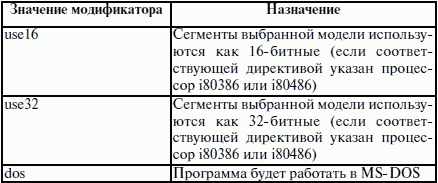 Необязательные параметры «язык» и «модификатор языка» определяют некоторые особенности вызова процедур. Необходимость в использовании этих параметров появляется при написании и связывании программ на различных языках программирования. Описанные нами стандартные и упрощенные директивы сегментации не исключают друг друга. Стандартные директивы используются, когда программист желает получить полный контроль над размещением сегментов в памяти и их комбинированием с сегментами других модулей. Упрощенные директивы целесообразно использовать для простых программ и программ, предназначенных для связывания с программными модулями, написанными на языках высокого уровня. Это позволяет компоновщику эффективно связывать модули разных языков за счет стандартизации связей и управления. |
|
||
|
Главная | В избранное | Наш E-MAIL | Добавить материал | Нашёл ошибку | Вверх |
||||
|
|
||||